- unwind ai
- Posts
- Run LLMs now on your Phone
Run LLMs now on your Phone
PLUS: Together AI's new inference stack, Eleven Labs new text-to-speech model
Gargi Gupta & Shubham Saboo
July 22, 2024
Today’s top AI Highlights:
Together AI announces new inference stack with Turbo and Lite endpoints
Run AI on your phone? Hugging Face’s new small language models make it possible
Eleven Labs’ latest text-to-speech model for high quality, low latency in 32 languages
Opensource AI on-call developer that jumps into incidents & alerts with you
& so much more!
Read time: 3 mins
Latest Developments 🌍
Together AI is launching its new inference stack, Together Inference Engine 2.0 (V2). This engine offers significantly faster decoding speeds than opensource vLLM and outperforms alternatives like Amazon Bedrock and Azure AI. Further, Together AI is also releasing Together Turbo and Together Lite endpoints, starting with Meta Llama 3, to provide a range of performance, quality, and pricing options.
Key Highlights:
Faster Decoding - V2 boasts a 4x faster decoding throughput compared to open-source vLLM. It also surpasses the performance of commercial solutions like Amazon Bedrock, Azure AI, Fireworks, and Octo AI by a 1.3x to 2.5x.
Together Turbo Endpoints - These endpoints prioritize speed and cost-effectiveness while maintaining quality comparable to full-precision FP16 models. They outperform other FP8 solutions and are 17x lower in cost than GPT-4o.
Together Lite Endpoints - Designed for maximum affordability and scalability, Together Lite utilizes optimizations like INT4 quantization. These endpoints offer exceptional quality relative to full-precision models, making high-quality AI more accessible.
Together Reference Endpoints - Delivering the fastest full-precision FP16 support for Meta Llama 3, these endpoints offer up to 4x faster performance than vLLM. They are ideal for tasks requiring the highest level of quality.
Technical Advancements - V2 incorporates cutting-edge research, including FlashAttention-3 kernels, speculative decoding algorithms, and quality-preserving quantization techniques. These ensure optimal performance, accuracy, and efficiency.
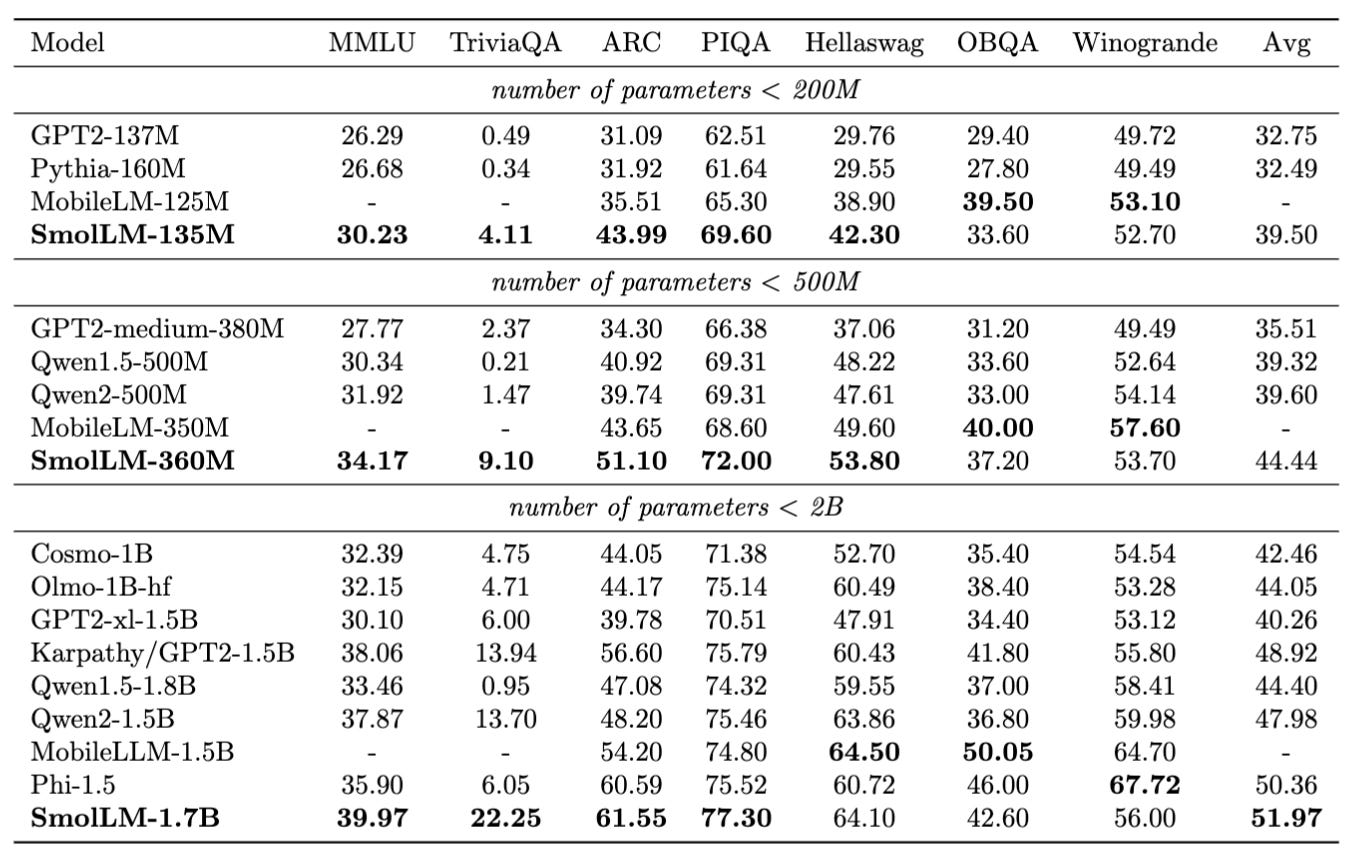
Hugging Face has introduced SmolLM, a new series of small language models (SLMs) designed for performance and efficiency. The SmolLM family comes in three sizes: 135M, 360M, and 1.7B parameters, each excelling in benchmarks against similar-sized models. These models are trained on SmolLM-Corpus, a meticulously crafted dataset also released by Hugging Face. SmolLM is designed to run locally, even on devices like smartphones, making it highly accessible for various applications.
Key Highlights:
High Performance - SmolLM consistently outperforms other SLMs in its size category across benchmarks, particularly in common sense reasoning and world knowledge tests. Notably, SmolLM-1.7B surpasses models like Phi1.5 and Qwen2-1.5B.
Efficient Training - Despite their strong performance, SmolLM models are trained on less data than some competitors. The 135M and 360M models are trained on 600B tokens, while the 1.7B utilizes 1T tokens, showcasing efficiency in data usage.
Focus on Data Quality - SmolLM-Corpus, the dataset used for training, is carefully curated and includes Cosmopedia v2, FineWeb-Edu, and Stack-Edu-Python. This focus on high-quality, education-oriented data contributes to the models’ robust capabilities.
Local Deployment - Designed for accessibility, SmolLM models can run locally on devices with limited resources. Hugging Face emphasizes their small memory footprint, making them suitable even for smartphones, and provides ONNX checkpoints for broader compatibility.
Quick Bites 🤌
Eleven Labs has introduced Turbo v2.5, their new text-to-speech model supporting 32 languages, including new additions like Vietnamese, Hungarian, and Norwegian. It offers 3x faster performance for many languages and a 25% speed increase for English, enabling high-quality, low-latency conversational AI.
OpenAI is in discussions with Broadcom to develop a new AI chip to reduce its dependence on Nvidia and enhance its supply chain. Led by CEO Sam Altman, the aim is to secure the necessary components and infrastructure for running advanced AI models.
Google, OpenAI, Microsoft, Amazon, and other major AI companies have formed the Coalition for Secure AI (CoSAI) to promote secure-by-design AI. CoSAI aims to create best practices, address AI security challenges, and provide open-source tools within the OASIS framework.
😍 Enjoying so far, share it with your friends!
Tools of the Trade ⚒️
Merlinn: AI-powered on-call engineer to provide real-time insights and root cause analysis for production incidents. It integrates with tools like Slack, Datadog, and Jira to manage incidents more efficiently and improve your on-call performance.

Guardrails Server: Deploy guardrails for your language models on the cloud, making local deployment to the cloud seamless. It supports the OpenAI SDK and offers cross-language compatibility for use in any language that supports the OpenAI SDK.
FlowTestAI: AI-powered opensource IDE designed to create, visualize, and manage API-first workflows. Describe your API workflows in natural language, and it visualizes API interactions, and performs end-to-end contextual testing.
Awesome LLM Apps: Build awesome LLM apps using RAG for interacting with data sources like GitHub, Gmail, PDFs, and YouTube videos through simple texts. These apps will let you retrieve information, engage in chat, and extract insights directly from content on these platforms.

Hot Takes 🔥
agents will probably generate order of magnitude more revenue than chatbots but both will end up being tiny easter eggs to fund the capex for superintelligence ~
roonI don’t think OpenAI is delaying the new voice mode over moans or meth recipes.
It’s probably because sufficiently advanced voice AI has the potential to induce psychosis 😵💫 ~
Pliny the Prompter
Meme of the Day 🤡
Founders dropping out of Stanford and CMU PhD programs raising money for their AI startups.
With no product, no revenue, and no idea.
— Rohit Mittal (@rohitdotmittal)
9:44 PM • Jul 17, 2024
That’s all for today! See you tomorrow with more such AI-filled content.
Real-time AI Updates 🚨
⚡️ Follow me on Twitter @Saboo_Shubham for lightning-fast AI updates and never miss what’s trending!
PS: We curate this AI newsletter every day for FREE, your support is what keeps me going. If you find value in what you read, share it with your friends by clicking the share button below!
Reply