- unwind ai
- Posts
- OpenAI Releases GPT-4o Mini
OpenAI Releases GPT-4o Mini
PLUS: AI Developer workstation for $15000, Mistral AI & Nvidia's new AI model
Gargi Gupta & Shubham Saboo
July 19, 2024
Today’s top AI Highlights:
OpenAI releases its smallest and cheapest GPT-4o mini model
Jim Keller’s Tenstorrent releases new AI devkits and workstations
Mistral AI and Nvidia team up for a powerful new language model
Google’s new AI-powered text-to-video presentations tool
& so much more!
Read time: 3 mins
Latest Developments 🌍
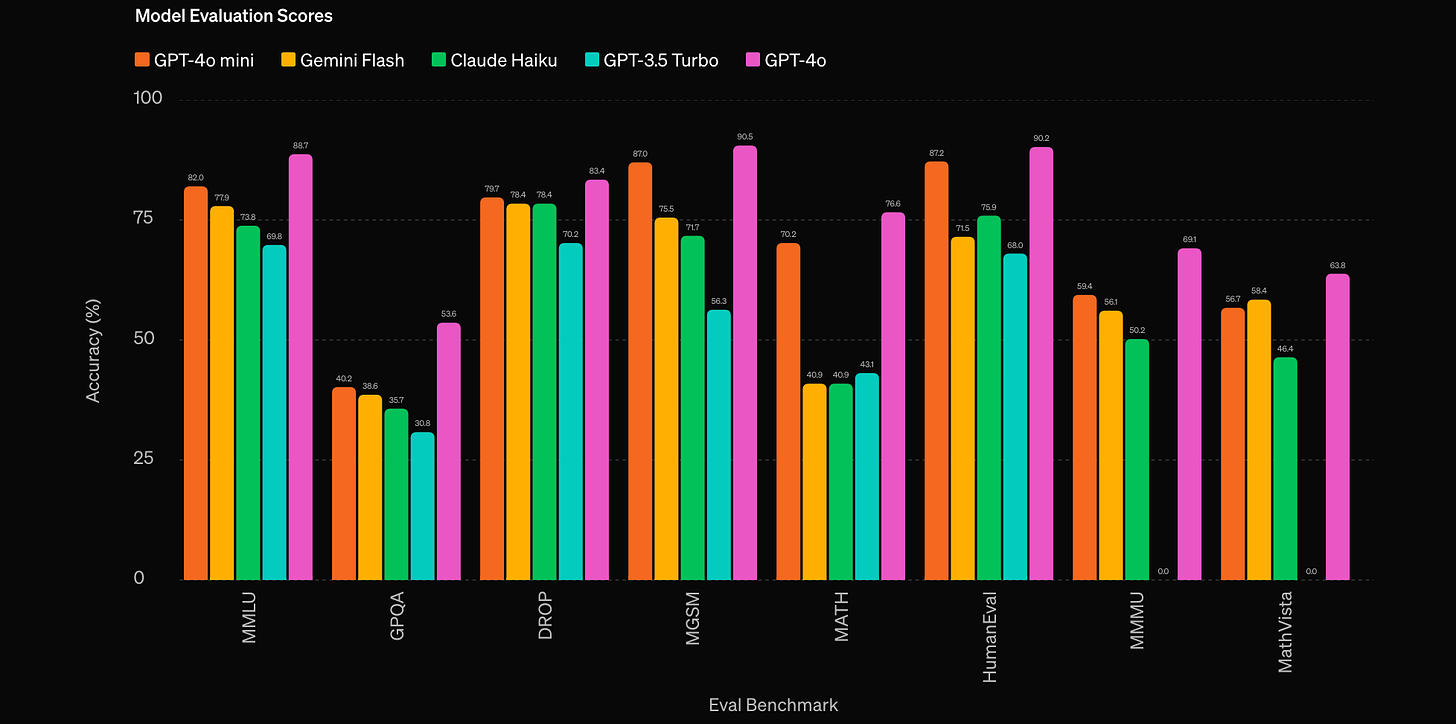
OpenAI has launched GPT-4o mini, its most cost-effective small multimodal model yet. It is 60% cheaper than GPT-3.5 Turbo and boasts excellent capabilities at a significantly lower price point. It achieves an impressive 82% on MMLU and outperforms GPT-3.5 Turbo in various tasks. This new model opens doors for developers to build a wider range of AI applications without breaking the bank.
Key Highlights:
Multimodality - GPT-4o mini supports text and vision in the API, with support for text, image, video, and audio inputs and outputs coming in the future.
Context Window and Output Tokens - The model has a context window of 128K tokens, supports up to 16K output tokens per request, and has knowledge up to October 2023.
Slashed Prices - Priced at $0.15 per million input tokens and $0.60 per million output tokens, GPT-4o mini is considerably cheaper than previous models.
Performance - GPT-4o mini excels in academic benchmarks for textual intelligence and multimodal reasoning. It outperforms GPT-3.5 Turbo as well as other models like Gemini Flash and Claude Haiku across MMLU, math, coding, and multimodal reasoning tasks.
Availability - GPT-4o mini is now available as a text and vision model in the Assistants API, Chat Completions API, and Batch API. In ChatGPT, Free, Plus and Team GPT-4o will replace GPT-3.5. Enterprise users will also have access starting next week.
Tenstorrent, the AI chip company led by renowned engineer Jim Keller, has released new devkits and AI workstations built around their latest Wormhole AI accelerators. This is the first time they’re offering complete workstations alongside their devkits. Tenstorrent’s Wormhole architecture is designed to be more powerful and efficient than its predecessor, Grayskull. Their commitment to a RISC-V processor ISA and open-source software sets them apart in the AI acceleration market.
Key Highlights:
Powerful Hardware - The Wormhole accelerators, manufactured using a 12nm process, boast 80 Tensix+ cores each and offer up to 328 TOPS of compute performance.
Devkits and Workstations - Tenstorrent is offering two Wormhole-based PCIe cards: the n150 (single chip) and the n300 (dual chip). For those seeking a complete system, the TT-LoudBox and TT-QuietBox workstations each house 4 n300 cards, providing a total of 8 Wormhole chips in a powerful 2x4 mesh configuration.
Workstations - The difference between both workstations lies in the cooling and CPU configuration, with the TT-LoudBox opting for air cooling and Intel Xeon processors, and the TT-QuietBox utilizes liquid cooling and an AMD EPYC processor.
Availability - The n150, n300, and TT-LoudBox are currently available for purchase on Tenstorrent’s website. The TT-QuietBox is available for pre-order and is expected to ship within the next 8-10 weeks.

Left: Wormhole-based n300 Devkit PCIe Card, Right: TT-QuietBox Workstation
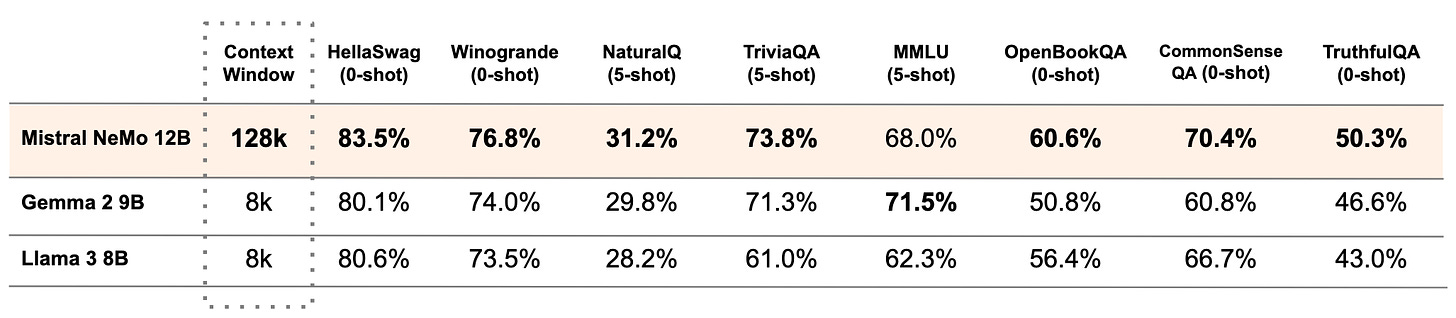
Mistral AI has released Mistral NeMo, a new 12B language model developed in partnership with Nvidia. Available under the Apache 2.0 license, this powerful model boasts a 128k context window and excels in reasoning, knowledge, and coding tasks for its size. Mistral NeMo is designed to be easily integrated into existing systems as a replacement for the Mistral 7B model.
Key Highlights:
Performance - Mistral NeMo outperforms Gemma 2 9B and Llama 3 8B on reasoning, commonsense, and truthfulness benchmarks. It also exhibits remarkable fluency in numerous languages, including French, German, Spanish, Italian, Portuguese, Chinese, Hindi, and more.
Tokenization - The model utilizes “Tekken,” a new tokenizer trained on over 100 languages. Tekken compresses text and code more efficiently than other tokenizers, particularly in languages like Chinese, Korean, and Arabic.
Instruction Following - The instruction-tuned version demonstrates major improvements in following complex instructions, logical reasoning, multi-turn conversations, and generating high-quality code compared to Mistral 7B.
Availability - Weights for both the base and the instruct models are hosted on HuggingFace. The model is also packaged in a container as Nvidia NIM inference microservice.
Quick Bites 🤌
Meta is withholding its next multimodal AI model from the EU due to “lack of clarity from regulators there.” This follows a similar move from Apple as they too won’t be releasing Apple Intelligence in the EU due to similar reasons. (Source)
Knowledge graphs for better RAG capabilities are catching significant momentum. Samsung is acquiring UK-based knowledge graph startup Oxford Semantic Technologies to enhance its AI capabilities. By utilizing knowledge graphs to semantically map users’ information, Samsung aims to provide personalized and secure on-device AI experiences. (Source)
TSMC’s more than 50% of revenue now comes from high-performance computing, driven by strong demand for AI chips. The company reported better-than-expected profit yesterday and raised its revenue growth outlook for 2024, expecting AI spending to remain high. (Source)
Google has started testing Gemini-powered video presentations Vids app in Google Workspace Labs. You can upload your documents, slides, voiceovers and video recordings, and Gemini with create video presentations with stock footage. This is not to be confused with text-to-video models like Google’s Veo. (Source)
😍 Enjoying so far, share it with your friends!
Tools of the Trade ⚒️
TalkTastic: Using your voice instead of manually typing everything in any app on macOS. It offers accurate dictation and smartly rewrites even when you stutter, based on the context of what you see on your screen. It ensures privacy by only listening and taking snapshots when you command.
Traceloop: Monitor your LLMs for issues like hallucinations and malfunctions, for consistent and reliable outputs. It provides real-time alerts, backtesting capabilities, and debugging tools for prompts and agents, all with easy installation and seamless integration.
LangSmith Playground: Quickly build and compare multiple prompts and model configurations side-by-side without switching tabs. It lets you test, iterate, and evaluate changes efficiently in a single view.
Awesome LLM Apps: Build awesome LLM apps using RAG for interacting with data sources like GitHub, Gmail, PDFs, and YouTube videos through simple texts. These apps will let you retrieve information, engage in chat, and extract insights directly from content on these platforms.

Hot Takes 🔥
We don’t think anymore, we just hack LLMs. ~
Pedro DomingosYears of SaaS software have messed with people’s heads when thinking about AI. Companies & schools are used to outsourcing R&D - software vendors build products & organizations implement them.
For AI, no one has special insight. Folks will need to do R&D themselves to get ahead ~
Ethan Mollick
Meme of the Day 🤡

That’s all for today! See you tomorrow with more such AI-filled content.
Real-time AI Updates 🚨
⚡️ Follow me on Twitter @Saboo_Shubham for lightning-fast AI updates and never miss what’s trending!
PS: We curate this AI newsletter every day for FREE, your support is what keeps me going. If you find value in what you read, share it with your friends by clicking the share button below!
Reply