- unwind ai
- Posts
- Google Gemini with 2M Context
Google Gemini with 2M Context
PLUS: Gemma 2 models released, Meta's LLM Compiler models
Shubham Saboo & Gargi Gupta
June 28, 2024
Today’s top AI Highlights:
Google releases Gemma 2 models, Gemini 1.5 Pro with 2M context
OpenAI uses GPT-4 to identify coding mistakes of GPT-4
Meta releases LLM Compiler models for code optimization and compiling
Character.AI’s new feature lets you talk with AI characters on call
& so much more!
Read time: 3 mins
Latest Developments 🌍
Google announced new additions to their lightweight open Gemma models, Gemini 1.5 Pro with 2 million tokens context, and context catching in the Gemini API last month at the I/O event. All three have been made available.
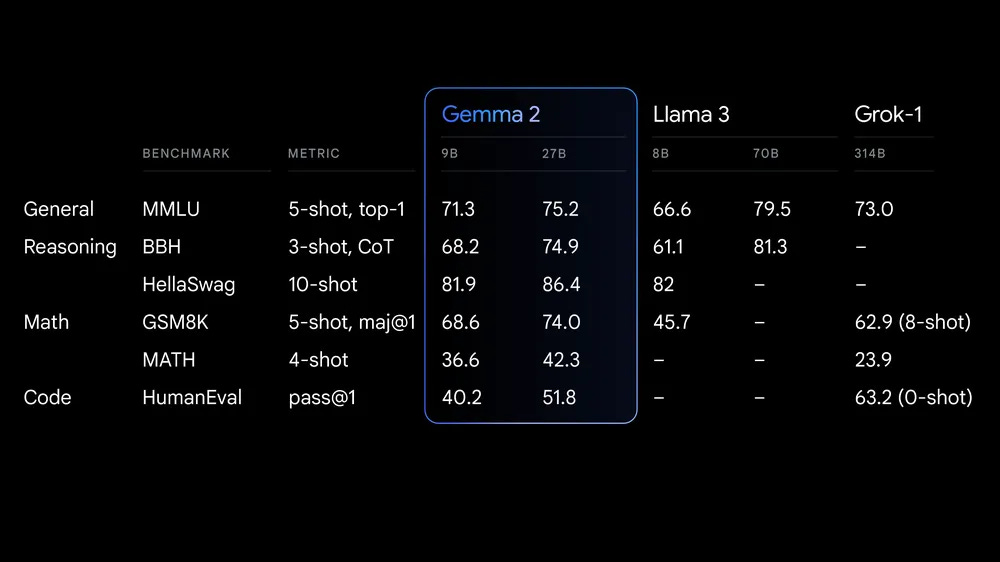
They have released Gemma 2 models in two sizes - 9B and 27B parameters. The 2B parameters model will be available soon. These models perform better than the first gen, outperforming other open models in their size category and competing with models 2x their size. Gemma 2 is now available in Google AI Studio, and their weights can be downloaded from Kaggle and Hugging Face.
Key Highlights:
Architecture - Gemma-2 models feature a decoder-only transformer architecture with 8k token context length and Rotary Position Embeddings. Major improvements include interleaving local-global attentions and Grouped-Query Attention for increased efficiency.
Training Approach - The 2.6B and 9B models were trained using knowledge distillation rather than traditional next token prediction, using large models to provide richer training data. This method significantly enhances small model performance, showing up to 10% improvement on benchmarks.
Training Data - The 27B model was trained on 13 trillion tokens of primarily English data, the 9B model on 8 trillion tokens, and the 2.6B on 2 trillion tokens. These tokens come from various data sources, including web documents, code, and science articles.
Cost and Efficiency - The 27B model is designed to run inference efficiently at full precision on a single Google Cloud TPU host, NVIDIA A100 80GB GPU, or NVIDIA H100 GPU, significantly reducing costs while maintaining high performance.
Performance - Gemma 2 9B outperforms Mistral-7B and Llama-3 8B across various benchmarks including MMLU, GSM8K, AGIEval, and HumanEval. The 27B model competes strongly on these benchmarks with Llama-3 70B and Grok-1 (314B).
Additionally, Google has also released “code execution” feature in Gemini API that enables the model to generate and run Python code and learn iteratively from the results until it arrives at a final output. You can use this code execution capability to build applications that benefit from code-based reasoning and that produce text output.
Reinforcement learning from human feedback (RLHF) is a crucial step in training AI models. However, it is limited by the capacity of humans to correctly evaluate model output and this limitation will be more significant as AI models become more capable to outperform even seasoned experts.
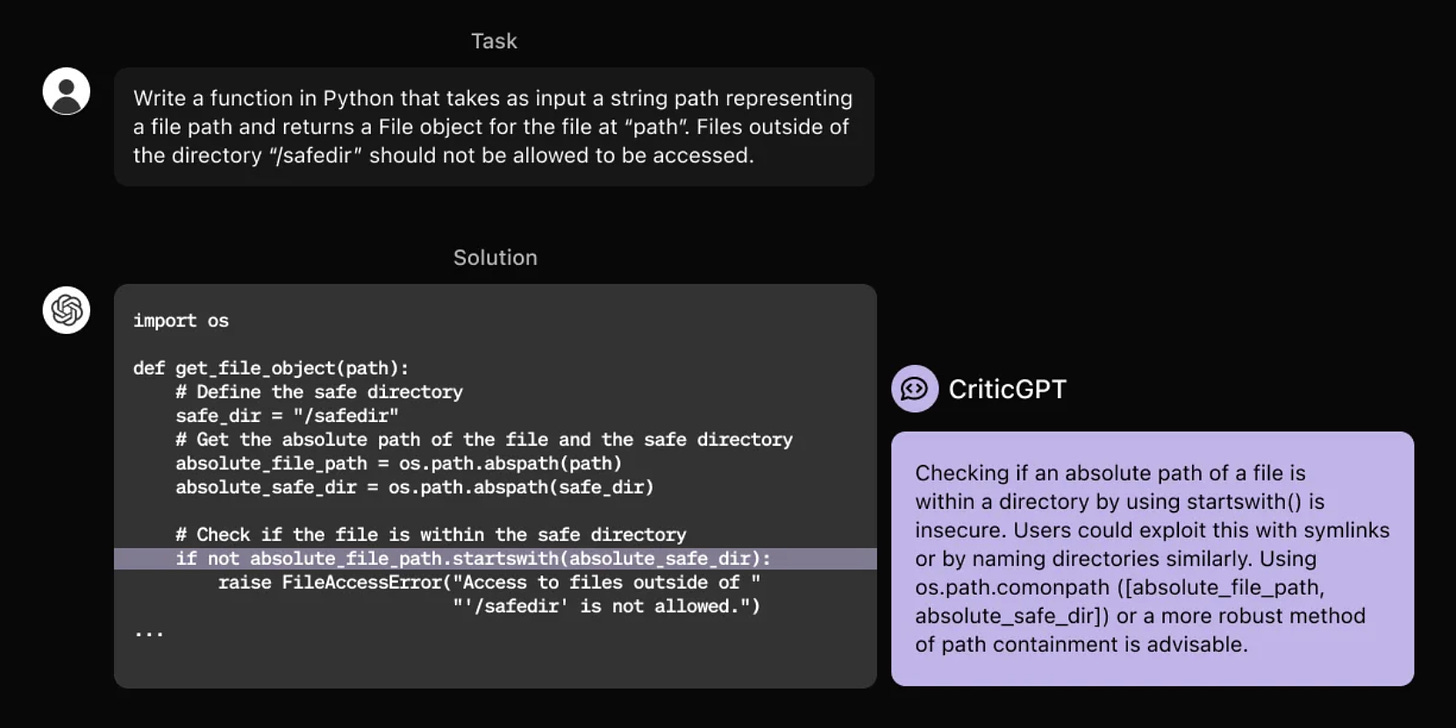
OpenAI has developed a “critic” model to help humans evaluate AI-generated code more effectively. This model called CriticGPT is based on GPT-4, and has been trained to catch errors in ChatGPT’s code output. This new method of scalable oversight could be successful in ensuring the reliability of AI systems.
Key Highlights:
Training - CriticGPT reviews AI-generated code and provides natural language critiques to highlight errors. The training involved a process called “tampering,” where human contractors intentionally introduced bugs into the code. The model then learned to identify these bugs by comparing its critiques to human-written explanations.
Performance and Application - CriticGPT was preferred over human critiques in 63% of cases and detected more bugs than human contractors. CriticGPT identified 85% of inserted bugs, compared to 50% by human reviewers and 64% by ChatGPT.
Broad Application - When evaluating training data for ChatGPT, CriticGPT identified hundreds of errors, including tasks beyond coding, such as general assistant tasks. When reevaluating “flawless” tasks, 24% of the critiques found substantial issues, compared to a 6% error rate when a second human reviewed without critiques.
LLMs are being extensively used for software engineering and coding tasks but their application in code and compiler optimization is still underexplored. Optimizing software code for better performance has been a persistent challenge for developers.
Meta has released the LLM Compiler, a family of models built on CodeLlama with additional code optimization and compiler capabilities. Available in two sizes: 7B and 13B, they offer enhanced capabilities including emulating compiler functions, predicting optimal code size reductions, and disassembling code.
Key Highlights:
Model Capabilities - LLM Compiler models can emulate compiler functions, predict optimal passes for code size, and disassemble code into its intermediate representations, achieving state-of-the-art results. Meta also offers fine-tuned versions of these models, which achieve impressive results.
Training and Data - The models are trained on a vast corpus of 546 billion tokens, including LLVM-IR and assembly code, and have been instruction fine-tuned to better interpret compiler behavior.
Performance - These models outperform comparable LLMs, including CodeLlama and GPT-4 Turbo, in optimizing code size and disassembly.
Fine-tuned models - Fine-tuned versions of these models show 77% of the optimizing potential of an autotuning search and achieve a 45% success rate in disassembly round trips, with a 14% exact match rate.

Character.AI launched a new feature yesterday called Character Calls. Now have two-way voice conversations with your favorite AI Characters, just like a regular phone call. You can get advice, practice your language skills, or simply have a fun conversation with an AI character.
You can switch between texting and talking anytime, choose from a variety of voices, and even interrupt the conversation with a tap. The feature is available for free on the Character.AI app.
😍 Enjoying so far, share it with your friends!
Tools of the Trade ⚒️
Dify: An open-source LLM app development platform that lets you build and deploy AI workflows quickly. You can integrate various models, craft prompts, manage agents, and monitor performance with its user-friendly interface.

Sider: Chat with any content on your screen using a simple double-tap gesture, helping you analyze, summarize, and extract text from screenshots. It also lets you interact with files and images, and supports multiple AI models like GPT, Claude-3, and Gemini 1.5.
Quill AI: Speeds up equity research by converting PDFs into spreadsheets with citation links and pulling tables from SEC filings efficiently. It also provides a dashboard summarizing earnings reports for quick analysis of the company.
Awesome LLM Apps: Build awesome LLM apps using RAG for interacting with data sources like GitHub, Gmail, PDFs, and YouTube videos through simple texts. These apps will let you retrieve information, engage in chat, and extract insights directly from content on these platforms.

Hot Takes 🔥
If we continue to increase the scale of funding for the models to $10 or 100 billion, and that might happen by 2025, 2026, or 2027, and the algorithmic improvements continue apace, the chip improvements continue apace, then there is a good chance that by that time we’ll be able to get models that are better than most humans at most things. ~
Dario AmodeiIf you are a student or academic researcher and want to make progress towards human-level AI:
>>>DO NOT WORK ON LLMs<<< ~
Yann LeCun
Meme of the Day 🤡
That’s all for today! See you tomorrow with more such AI-filled content.
Real-time AI Updates 🚨
⚡️ Follow me on Twitter @Saboo_Shubham for lightning-fast AI updates and never miss what’s trending!
PS: We curate this AI newsletter every day for FREE, your support is what keeps me going. If you find value in what you read, share it with your friends by clicking the share button below!
Reply