- unwind ai
- Posts
- Chinese AI Model Beats GPT-4o and Claude 3.5
Chinese AI Model Beats GPT-4o and Claude 3.5
PLUS: Hollywood-grade AI video generation, YouTube's AI tool to remove copyrighted music
Gargi Gupta & Shubham Saboo
July 09, 2024
Today’s top AI Highlights:
China’s first real-time multimodal AI model to rival GPT-4o
New company is bringing Hollywood-grade AI visual platform
YouTube’s AI tools to remove copyrighted music without losing your sound
This opensource AI voice assistant responds in near real-time
& so much more!
Read time: 3 mins
Latest Developments 🌍
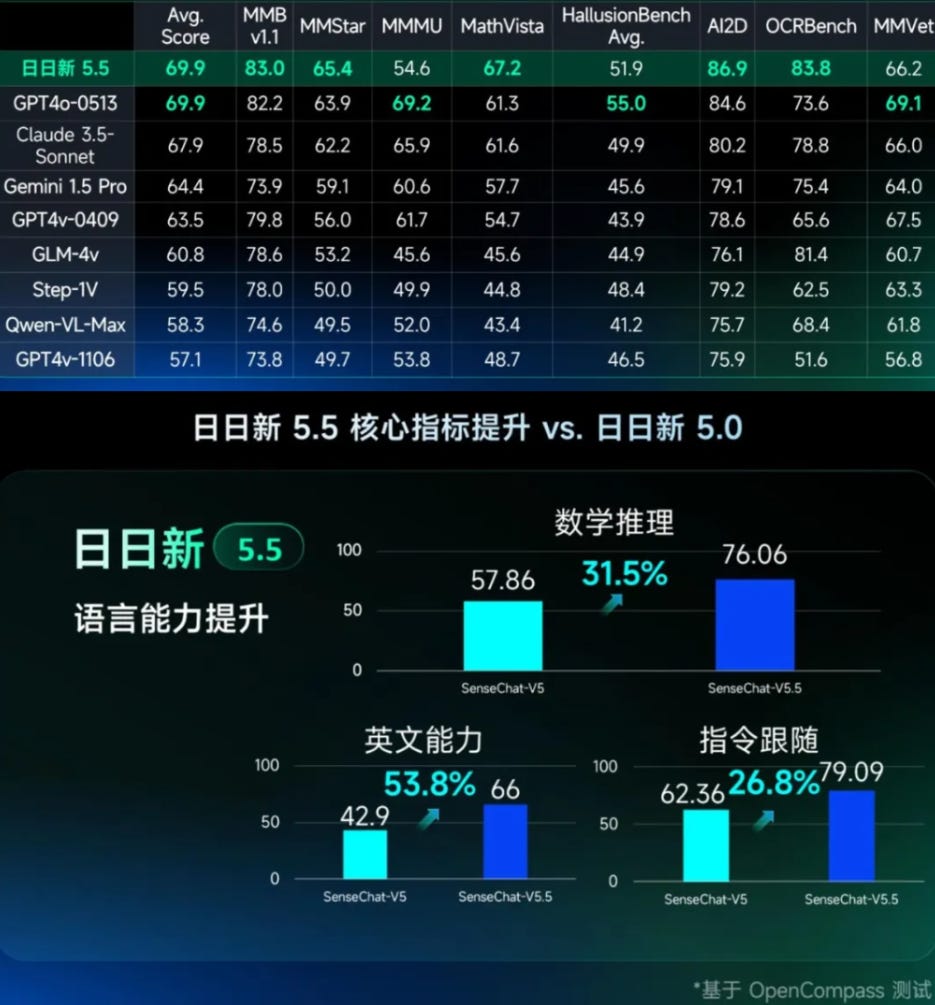
China’s AI progress shows that the Valley is not the only king. At the World Artificial Intelligence Conference, Chinese AI company SenseTime introduced its new multimodal AI model SenseNova 5o and the improved language model SenseNova 5.5. SenseNova 5o can process text, images, audio, and video, and is suitable for real-time interactions. The model outperforms state-of-the-art models like GPT-4o and Claude 3.5 Sonnet across most of the standard benchmarks.
Key Highlights:
Real-time Video Chat - Due to its vision capabilities, SenseNova 5o can recognize and describe individual objects by simply pointing a smartphone camera at the object while the AI app is running.
Improved Performance - SenseNova 5.5 achieves a 30% increase in performance over version 5.0, released just two months ago. It also outperforms leading AI models like GPT-4o, Claude 3.5, and Gemini 1.5 Pro.
Edge-based LM - SenseTime is also investing in edge-based language models. With SenseChat Lite-5.5, inference time has been reduced to 0.19 seconds, 40% faster than version 5.0, and inference speed has increased by 15% to 90.2 words per second.
AI Video Generator - SenseTime also demoed its video generation foundation model Vimi AI which can generate up to 1-minute clips from a single photo while providing control over facial expressions, lighting, and background.
The current AI video generation can be compared with AI image generation a few years earlier. It lacks the depth, details, and magic of storytelling. The technology has immense potential to overtake traditional storytelling which can’t go beyond real-world physics.
Entering this rapidly moving industry is Odyssey which is developing “Hollywood-grade visual AI,” to give filmmakers, game developers, and artists unprecedented control over AI-generated visuals. It’s an effort of a team that has previously delivered state-of-the-art AI and simulation systems at Waymo, Cruise, Meta, Nvidia, and has deep experience in computer graphics research and filmmaking.
Key Highlights:
Layered Generative Models - Odyssey utilizes four distinct models for geometry, materials, lighting, and motion, allowing for granular control over each element of a scene. This contrasts with single text-to-video models, which offer less flexibility.
Hollywood-Level Fidelity - Odyssey aims to create visually stunning and realistic results suitable for high-end productions. This is very important to counter the substandard often-unrealistic output of current tools.
Focus on Creative Control - A core principle for Odyssey is empowering storytellers, not replacing them. Their tools are being designed to integrate into existing production pipelines, so the users can direct and refine AI-generated content to match their vision.

Quick Bites 🤌
YouTube is updating its “Erase Song” feature with a new AI feature that will identify and remove copyrighted music from videos while keeping other audio elements intact. Creators can choose between “Erase Song” to target only the copyrighted audio or “Mute All Sound” to silence everything within specified timestamps.
The AI hardware industry is booming at rocket speed. Two weeks back Nvidia crossed $3 Trillion market cap to become the world’s most valuable company. Yesterday, Taiwan Semiconductor Manufacturing Co. (TSMC) briefly hit a $1 trillion market value. Analysts expect TSMC to raise its revenue guidance and possibly increase wafer prices due to strong market positioning. (Source)
This is probably the fastest AI Voice Assistant available today. Swift is an open-source voice assistant that uses Groq for fast inference of OpenAI Whisper (for transcription) and Meta Llama 3 for generating text responses.
😍 Enjoying so far, share it with your friends!
Tools of the Trade ⚒️
OpenContracts: Free, opensource tool for managing and analyzing documents, especially PDFs. It extracts layout features, generates vector embeddings, and performs both manual and automated annotations to make document data searchable and actionable with querying features.

ChatLabs: Interact with top AI models like ChatGPT, Claude, Gemini, and Llama 3 in one place for chatting, writing, web searching, and image generation. It also offers tools for managing AI prompts, generating images, AI web browsing, using voice input, and organizing chats.
Open LLM Explorer: Test leading language models from the Open LLM Leaderboard on your specific prompts and view the results and inference code easily. You can try it for free
Awesome LLM Apps: Build awesome LLM apps using RAG for interacting with data sources like GitHub, Gmail, PDFs, and YouTube videos through simple texts. These apps will let you retrieve information, engage in chat, and extract insights directly from content on these platforms.

Hot Takes 🔥
In the next 3 years, we will reach AGI!
Brace yourselves: job losses will skyrocket, and AI will become your new work partner.
Yet, ASI isn’t here to end us…yet. The future is closer than you think! ~
Eli BraginskiyIf intelligence is nonlinear, then the average person is pretty dumb. ~
Naval
Meme of the Day 🤡

That’s all for today! See you tomorrow with more such AI-filled content.
Real-time AI Updates 🚨
⚡️ Follow me on Twitter @Saboo_Shubham for lightning-fast AI updates and never miss what’s trending!
PS: We curate this AI newsletter every day for FREE, your support is what keeps me going. If you find value in what you read, share it with your friends by clicking the share button below!
Reply