- unwind ai
- Posts
- 12x Faster Inference for RAG
12x Faster Inference for RAG
PLUS: Microsoft's data flywheel for LLMs, Amazon Rufus available to all in the US
Gargi Gupta & Shubham Saboo
July 16, 2024
Today’s top AI Highlights:
Microsoft builds a data flywheel for LLMs post-training via Simulated Chatbot Arena
Fireworks AI launches FireAttention V2 for 12x faster inference on long context
Google Gemini might be scanning your files from Drive, secretly
Mem0 - The memory layer for Personalized AI
& so much more!
Read time: 3 mins
Latest Developments 🌍
Platforms like the LMSYS Chatbot Arena, which pits different chatbots against each other and uses human feedback to rank them, are valuable tools for improving LLM performance post-training. But it often involves resource-intensive and time-consuming human evaluations, creating a bottleneck in the speed and scale of LLM improvement.
To address this, Microsoft proposes “Arena Learning,” a training and evaluation pipeline fully based on and powered by LLMs. Arena Learning simulates these chatbot competitions using AI, eliminating the need for human involvement in the evaluation process. This simulated arena enables a continuous feedback loop for ongoing model improvement.
Key Highlights:
Automated Evaluation - Arena Learning employs an “AI judge” to assess simulated chatbot battles, mimicking human judgment and providing rankings, scores, and explanations for each interaction.
Iterative Improvement - The target LLM is repeatedly pitted against other state-of-the-art models, with each iteration generating data used to refine its capabilities through various training techniques.
Accurate Prediction - It demonstrates high consistency with the human-evaluated LMSYS Chatbot Arena, effectively predicting model rankings in a controlled offline environment.
Performance Gains - LLMs trained using Arena Learning show considerable improvement across multiple evaluation metrics, including Elo rankings, win rates, and benchmark scores.
Why it matters: Arena Learning could drastically reduce the time and cost associated with model evaluation so you can focus more on innovation and less on tedious processes. Removing the need for human annotators, it can scale your evaluations more effectively.

Fireworks AI previously released FireAttention, a specialized CUDA kernel within their proprietary LLM serving stack to speed up the serving of open-source models like Mixtral. Focusing on use cases with 1K token prompt and 50 generated tokens, it demonstrated a 4x speed increase compared to alternatives like vLLM, while maintaining comparable accuracy.
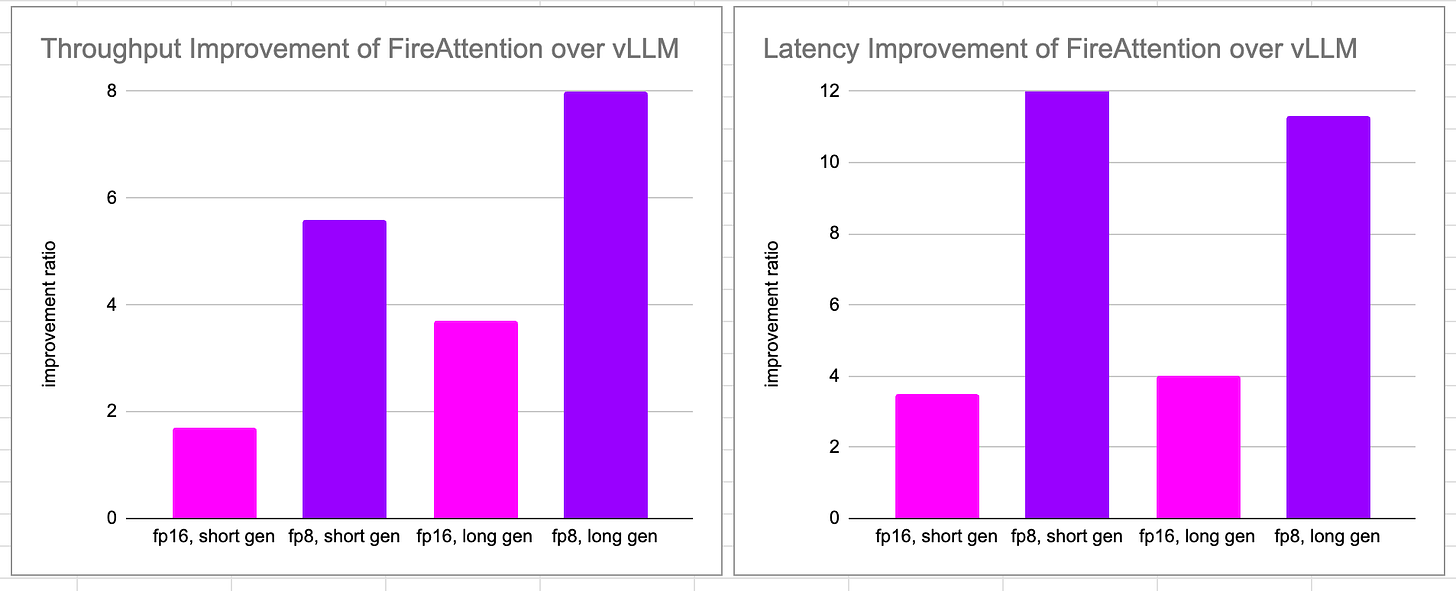
Now, Fireworks AI has released FireAttention V2 to tackle long context (8K-32K) inference. V2 incorporates specific optimizations for the Hopper architecture and a multi-host deployment mode for high-traffic scenarios. This resulted in up to 12x faster inference times compared to previous versions.
Key Highlights:
Beyond Needle in a Haystack - Fireworks argues that NIAH isn’t a sufficient benchmark for true long-context understanding. Instead, they utilize the RULER benchmarking library for multi-needle, variable tracking, and question-answering tasks.
Qwen 72B Excels - Fireworks found that among open-source models, Qwen 72B demonstrates the strongest performance on these more complex long context benchmarks.
Dominating Performance Across Contexts - FireAttention V2 consistently outperforms vLLM in both short-medium and long-generation tasks, showing high throughput and latency advantages of 1.7x to 8x depending on the specific configuration.
Multi-host Deployment for Better Throughput - FireAttention multi-host mode allows FireAttention to improve throughput by ~2x more while keeping latency improvement relatively intact.
Try now - Qwen 2 72b Instruct, Mixtral 8x7B Instruct and many other models are available for you to try right now on fireworks.ai and can produce with the abovementioned speed.
Why it matters: FireAttention V2 significantly improves LLM inference for high-traffic and long-context scenarios, improving user experiences. The focus on long-context tasks also pushes LLM evaluation beyond simple retrieval, better reflecting real-world application needs. As the scope of RAG and multi-agent applications increases, optimizations like this will become crucial for maintaining performance and efficiency.
Quick Bites 🤌
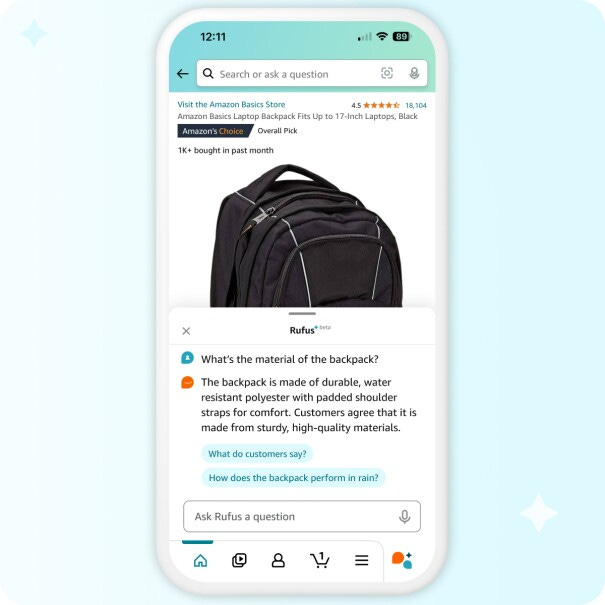
Amazon’s AI shopping assistant Rufus is now available for all Amazon customers in the US. Living in the bottom of the app, Rufus can answer your questions about product details, discovering and covering options, current and past orders, and even non-shopping related questions.
HP has introduced HP OmniBook Ultra, the world’s highest-performance AI PC with up to an industry-leading 55 TOPS of NPU performance. Powered by the newly launched AMD Ryzen AI 300 series processor especially designed for Copilot + PCs, it offers unparalleled performance and up to 21 hours of battery life.
Google’s Gemini has been scanning PDF files in Google Drive without user permission. An X user Kevin Bankston shared on the platform that Gemini automatically summarized his tax return in Google Docs without prompting it. The surprising part is that his Google Workspace extension is turned off in the settings but Gemini continues to scan his documents without permission.
😍 Enjoying so far, share it with your friends!
Tools of the Trade ⚒️
Mem0: Create personalized AI experiences by retaining information across sessions and continuously improving based on user interactions. It provides a straightforward API for easy integration into various applications for consistent and adaptive personalization.AI-Renamer: A Node.js CLI tool that renames files based on their contents using Ollama and LM Studio models like Llava and Llama. It extracts frames from videos with ffmpeg and uses the models to rename the files.

Booth.ai: No-code generative AI app builder to create powerful AI solutions in minutes. You can build custom tools for tasks like categorizing customer inquiries, analyzing PDFs, or automating tasks, using its library of 165+ nodes and various AI models.
Awesome LLM Apps: Build awesome LLM apps using RAG for interacting with data sources like GitHub, Gmail, PDFs, and YouTube videos through simple texts. These apps will let you retrieve information, engage in chat, and extract insights directly from content on these platforms.

Hot Takes 🔥
Synthetic data is dumb, no shot you get better models from it. Have you ever read the synthetic instructions? I never ask questions like that to LLMs ~
antonYou either die a hero or live long enough to become the next IBM. ~
Bojan Tunguz
Meme of the Day 🤡

That’s all for today! See you tomorrow with more such AI-filled content.
Real-time AI Updates 🚨
⚡️ Follow me on Twitter @Saboo_Shubham for lightning-fast AI updates and never miss what’s trending!
PS: We curate this AI newsletter every day for FREE, your support is what keeps me going. If you find value in what you read, share it with your friends by clicking the share button below!
Reply